

This post aims to provide more detail about how the .NET Framework is compromised, to give you a better understanding on the best ways to program using it.
In Part 1 of this series of tutorials we introduced the .NET Framework in broad terms. There’s a lot more going on under the hood than was presented in that tutorial and we will now hopefully try to explain what’s going on in more detail.
The Importance of the Runtime Engine
A key tenet that forms the backbone of everything .NET is its Runtime Engine. The .NET runtime engine virtualises interaction with an underlying operating system by providing common methods to the programmer regardless of what the low-level functions might be. In this way the programmer doesn’t have to consider the specific operating system that will be in use –the required functionality is provided through the runtime.
The programmer simply consumes generic methods (to open a file, for example) and the runtime engine handles the operating system specific implementation. That way, an enormous amount of programming overhead that used to fall heavily at the software developer’s door is removed and is instead managed by vendors who produce the runtime engine (Microsoft in this case (or via the Mono project on Linux.))
In order for this to work Microsoft had to introduce new concepts that will be discussed in detail:
- Managed and Unmanaged Code.
- Just-in-Time Compilation.
- The ‘Common Type System’ (CTS) and the ‘Common Language Specification’ (CLS).
- The .NET Assembly.
- Software Deployment Scenarios.
- Putting It All Together – The .NET Framework Stack.
- Visual Programming in .NET.
Managed Versus Unmanaged Code
When we talk about managed code or unmanaged code we are really referring simply to how the memory management is handled.
In order to fully understand the benefit gained through managed code, you must appreciate how memory is accessed on a computer. For the purposes of discussion, memory can be thought of as a large store room where you can reserve storage space in fixed cubic units (for example, 1m3) You can’t use any space until you’ve asked the store manager (the computer) to reserve it for you. If you want to reserve more than one unit of space at any one time, the units must be next to each other. To make his indexing system easier to use the store manager has numbered adjacent units sequentially with respect to one another. If you’ve reserved more than one unit, your storage area is identified by the reference number of the first unit.
In this analogy the unit reference number is the memory address – the means by which you identify a specific storage area (or memory location.) When you want someone to look at what you’ve stored you could go and collect everything, copy it all and take the copies to that person. Alternatively, you could simply write the unit reference number on a piece of paper, give it to the person concerned so they can go and have a look for themselves. Obviously, there’s a lot less work involved in giving someone a unit reference number than in having to copy everything and carry it around. The piece of paper is essentially a ‘memory address pointer’ in this case. Because people are inherently lazy memory address pointers are often referred to as ‘memory pointers’, or simply ‘pointers’.
In computer programming terms, pointers are references to areas of memory storage. Pointers provide a means to pass the reference to a large amount of data between different parts of a program without having to pass that data directly – this implies a massive saving in terms of incidental memory consumption and program efficiency. For example, if we passed a text value of 500 characters (500 bytes) between 4 methods we’d have created 2000 extra bytes of information (each method call would result in a complete copy of the data.) Instead, we can pass a pointer to that data (that’s only 4 bytes for a 32bit operating system) and let the methods simply look at the stored data. That’s about a 2 kilo-byte saving in our simple example!
Something to point out while discussing memory space is that the pointer itself has no concept of the size of the memory space it relates to. Our reference number simply indicates where the start of reserved memory is located. It is relatively easy to write more information than there was space allocated and that could mean loss of data and, even worse, corruption of memory being used by another process which could lead to application or operating system instability issues. Something else you may find a bit confusing is that the pointer value being passed around is stored in memory too (so it’s a value held in memory that’s a pointer to the address at which other values are stored in memory – easy, huh?!)
So, now that you understand how memory addressing and pointers work, back to the advantages of managed code…
In an unmanaged code environment (i.e. pretty much all software development prior to the introduction of .NET and Java) software developers had to explicitly request memory resources from the operating system and explicitly release those resources when the program had finished with them. This in itself introduced a significant programming overhead, not to mention countless hours debugging faulty memory management routines. With the introduction of the managed code environment, the .NET Framework took responsibility for handling all memory allocation and revocation. This removed a great burden from the software developer as well as centralising memory management procedures leading (in principle) to a more efficient memory allocation and revocation scheme, and one that was less open to certain types of malicious attacks (such as buffer overflow).
To understand the benefit to the programmer, consider storing some text in a variable, using that data and then disposing of the variable afterwards. In an unmanaged code environment you would have to explicitly write code to do the following:
- Declare a variable (created as a pointer).
- Request the required memory resources (amount of space required to store the text), setting the pointer to the start of the reserved memory.
- Copy the text into the variable (the memory space referenced by the pointer).
- Use the variable as needed.
- Explicitly release the memory resources reserved by the pointer variable.
- Dispose of the variable (release the pointer).
As you can see, in the unmanaged code environment the developer has to write a fair amount of code simply to store the data and release the reserved memory afterwards. We haven’t even considered what might happen if ‘use of the data’ results in a software error – to be sure that the memory resources were released some error handling code would also have to be written (otherwise the memory resources may be orphaned and become unavailable until the application was terminated.)
The same functionality in managed code could be written as:
- Declare a variable, and copy the text to it.
- Use the variable.
Memory allocation and revocation is handled implicitly by the runtime so no explicit memory requests are required. Even better, if a software error occurs the runtime’s ‘garbage collector’ would automatically release the memory resources it deemed finished with.
It is worth mentioning as a final thought on managed code that while implicit memory management might seem like the solution to all memory allocation woes there are situations where it can introduce problems of its own.
The memory management system’s ‘garbage collector’ (the process responsible for cleaning up reserved memory resources that are no longer required) only runs periodically – and normally subject to processor demands. This means that if memory and processor resources on a particular computer are tight then memory may remain in use long after it has been finished with by the application.
The developers of the .NET Framework realised this and provided methods to force immediate garbage collection if required, but they are not recommended for general use and should only be called in exceptional circumstances.
Just-in-Time (JIT) Compilation
Before the .NET Framework was released, Windows applications were compiled as native binary files. A ‘native binary’ means the application was compiled directly to machine code (binary data that can be executed directly by the operating system.) This led to additional work for the development and testing teams (when compared with .NET).
Applications written for the .NET Framework are not compiled into native binary code. They are in fact only partially compiled, into an intermediate language (Microsoft Intermediate Language (MSIL)). The reason for this will become clear later when we explain some of the other concepts that the .NET Framework introduced.
The .NET Runtime employs a compilation scheme known as Just-in-Time (JIT) compilation. It works by compiling from MSIL in real-time when the application is running. This may sound like a drawback from a code execution efficiency stance (as the software has to be compiled on the fly when it’s being used) but it does present several benefits and in many cases can make the software more efficient.
When a Windows application that is compiled as a native binary file is launched, all of the functionality associated with the application has to be loaded at once. This includes all shared libraries that are referenced by the application. The immediate memory footprint for a large application is therefore massive – even if three quarters of the functionality isn’t being used.
When a .NET application is launched the JIT compiler can compile individual classes within the application on an on-demand basis. This means that a .NET application is likely to start up more quickly and may use significantly less memory resources during its execution lifecycle (from launch to termination). As mentioned, there are some circumstances when JIT compilation may represent efficiency losses such as for a large program that provides a broad functional scope, all of which will be required pretty much from launch. Microsoft has thought of this and provides a native code compiler that can be used to pre-compile part of or all of an application. The native code compiler must be run after the .NET application has been installed (since native code is operating system specific.)
The JIT compiler is part of the Virtual Execution System (VES) provided within the .NET Runtime. The VES provides the environment within which managed code is executed. The main purpose of the VES is to provide the capability to compile intermediate language into native machine code for execution by the operating system.
The .NET Common Language Specification
The .NET Framework defines a Common Type System (CTS) to ensure that all managed code is self-describing. It is effectively a set of pre-defined data-types that can be used in .NET programming languages.
Prior to .NET, interaction between software modules written in different programming languages was often troublesome. For example, the data-type used to store text in C++ is different from that used in Visual Basic (C++ uses an array of 8-bit ASCII characters and Visual Basic uses a more complex, but more flexible, solution involving pointers and arrays of 16-bit Unicode characters.)
This led to a number of software interoperability issues that plagued developers and cost time and effort to resolve. The Component Object Model (COM) made some progress in overcoming these obstacles but some inconsistencies still existed.
By introducing the CTS, Microsoft enforced the use of common data-types across .NET programming languages which implied a robust type-and-code-verification infrastructure in its own right.
Understanding that a specific .NET programming language may not support every feature defined by the CTS, Microsoft defined the Common Language Specification (CLS.) The CLS represents a subset of the CTS and programming constructs that all .NET programming languages must adopt – it therefore forms the basis of transparent programming language interoperability in .NET. In other words, provided you develop .NET types (structures, classes, etc.) that only expose CLS-compliant features you can be sure that any .NET aware language can consume them.
The .NET Building Block – Assemblies
As part of the painfully large new vocabulary that Microsoft introduced with the release of the .NET Framework ,they felt that ‘executable’ and ‘library’ didn’t really provide a suitable descriptive context for compiled .NET code. Instead, all compiled .NET modules are referred to as ‘assemblies’.
There are good reasons for this it turns out. All .NET types (be it the built-in FCL types or custom types produced by software programmers) are self-describing – the CTS enforces this, remember. The way that assemblies manage to describe the types they contain is through metadata.
You are probably wondering what metadata is about now. Metadata is a generic term used for ‘data that describes data’ (i.e. descriptive data rather than content.)
For example, most people are familiar with Dolby Digital Surround Sound. It provides a means to transmit audio information as a digital stream, and the main component parts of the stream are: the audio channels and metadata. The audio channels provide the content, and could be decoded and played without any further intervention. What the metadata does is help describe the audio channels, to put them in context.
Ever listened to a director’s commentary on a DVD? How did the DVD player know that the audio was the commentary rather than the normal 5.1 channel surround sound track for the movie? Yes, you guessed it, it was through a metadata description of the audio channel that described it as the director’s commentary!
Getting back to .NET, in addition to the type description metadata, every assembly must include an ‘Assembly Manifest’. The assembly manifest contains all the metadata needed to specify the assembly’s version information, security identity, scope, and references to the resources (e.g. dependent assemblies) that the assembly requires. The manifest is produced implicitly during the assembly compilation process and for the most part you can ignore it, but its important to understand that it exists and that it may hold the answers to why your software doesn’t work.
Assemblies can exist as a single file or as a number of files – this is one aspect in which the previous ‘executable’ and ‘library’ definitions might have failed us. When an assembly is compiled as a single file the assembly manifest is embedded within that file. When an assembly is spread across several files the manifest can be contained within one of those files (provided it is a compiled file) or in a separate file. In most cases you will only be dealing with single file assemblies, but again it’s worth mentioning in case you come across that rare occurrence: the multi-file assembly!
.NET Deployment Scenarios
Back in the days of procedural programming you had to use system directories for your shared libraries or keep all of your libraries with the application. This meant installers either risked having shared libraries overwritten by others with the same name or they dramatically increased their installation footprint by having to maintain all their application libraries privately.
COM attempted to overcome these issues by introducing the concept of registration of libraries with the operating system so that they were globally visible. You couldn’t use a COM library unless it was registered but unfortunately versioning was left out of the COM specification, meaning that registering one version of a COM library wiped out any reference that might have already existed to a previous version of the library. If the new version didn’t maintain binary compatibility with the old version then any applications that relied on the old version would usually fail to run.
With the .NET Framework, Microsoft tried take advantage of the best aspects of both these historical techniques to overcome the problems associated with them. The .NET Framework introduced a new registration scheme whereby assemblies can still be registered with the operating system for the purposes of sharing. Shared assemblies are deployed to a common storage area called the Global Assembly Cache (GAC.) This time side-by-side versioning is supported, meaning v1.0.0.0 and v1.2.3.4 of an assembly can both be deployed to the GAC and the separate versions can still be used independently by applications that require them.
Assemblies may also be distributed privately with an application. It is worth noting, however, that the .NET Runtime always looks for assemblies in the GAC before anywhere else (even before checking the application’s local directory.) If an assembly has been loaded and it is removed from the GAC while it is in use, the removal will work but the assembly may remain resident until the computer is restarted – its useful to know this when you are debugging a .NET assembly that’s deployed to the GAC as your changes may not be propagated until the next time you reboot!
The .NET Framework also introduced a new concept of application maintenance. ‘ClickOnce’ is a technology that allows software developers to release self-updating applications. ClickOnce applications can be installed locally on a user’s computer or run directly from a source location in an online only mode.
ClickOnce applications can be accessed via a web page, a network file share, etc. When deployed to the user’s local computer, the application will regularly check its source location for newer versions and, either optionally or mandatorily, can update itself to the new version. There are two other software deployment alternatives to ClickOnce. The first is a simple copy and paste (often referred to as XCOPY: copying the application files and overwriting any existing versions if they exist), and the second is a Windows Installer package. The installer package option has the advantage of appearing more professional by providing an installation wizard that guides the user through the installation process. This does mean additional programming overhead (producing the installer package) so for small application deployments this may not be deemed worthwhile.
Putting It All Together – The .NET Framework Stack
Really, the .NET Framework can be thought of as a number of layers building upon one another. The diagram below represents the stack of layers.
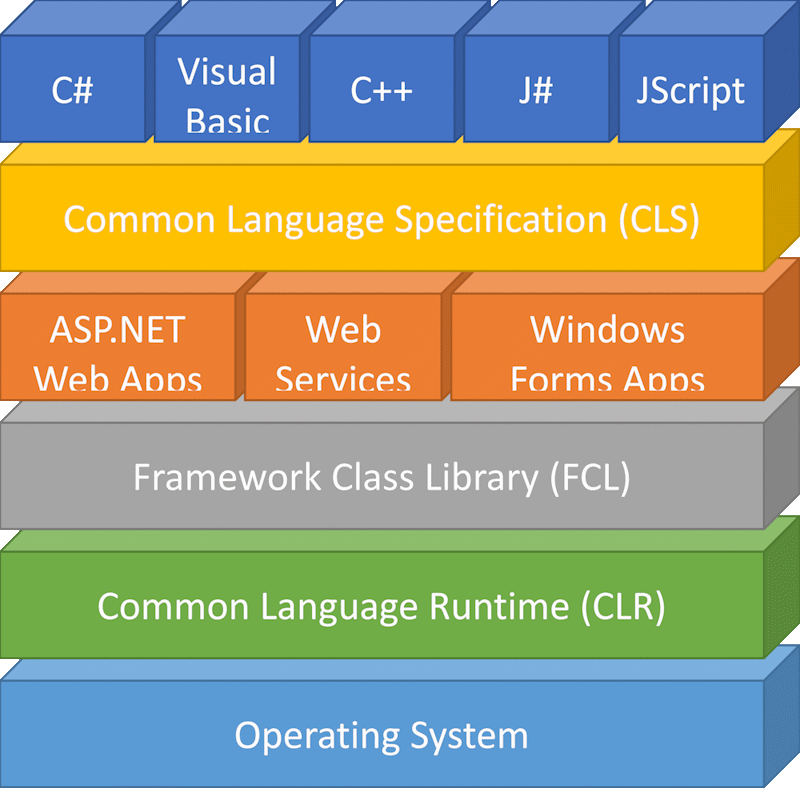
Software is developed in any of the five CLS compliant languages, making use of the FCL and proprietary .NET libraries. The software is partially compiled into assemblies that contain intermediate language (MSIL) and metadata that describes the contents of the assemblies. When the application is launched the CLR performs the JIT compilation of the MSIL code at runtime, producing machine code that can run on the specific operating system.
Visual Programming in .NET
As part of the .NET Framework rollout, Microsoft released a new version of its official Integrated Development Environment (IDE), Visual Studio.
The .NET version of Visual Studio was a massive improvement over its predecessors with feature rich GUI designers, a content aware source code editor, integrated build facilities, extensive debugging capabilities, and IntelliSense.
IntelliSense is Microsoft’s context-based code documentation viewer and auto-completion tool, and it runs in real-time helping a programmer to produce their software more quickly by providing pop-up prompts with documentation snippets describing properties and methods (and their parameters) and auto-completion suggestions after a couple of characters of a phrase have been typed.
Visual Studio also provided enhanced refactoring tools, enabling a programmer to rename an entity (class, variable, etc.) throughout a project very quickly and easily.
The IDE provides a host of other tools that help simplify certain programming tasks (such as a server explorer that can be connected to a database and used to generate SQL statements, and the ability to integrate with source code control systems).
Visual Studio is a truly next-generation rapid application development (RAD) platform and it’s available in different versions from a free ‘hobbyist’ version called the Express Edition to a professional enterprise-level version called Team System. The Team System product series offers a complementary server-side product called Team Foundation Server that provides a source code version control system, a documental version control system, a team collaboration portal, a project management suite, automatic build facilities and a bug tracking system.